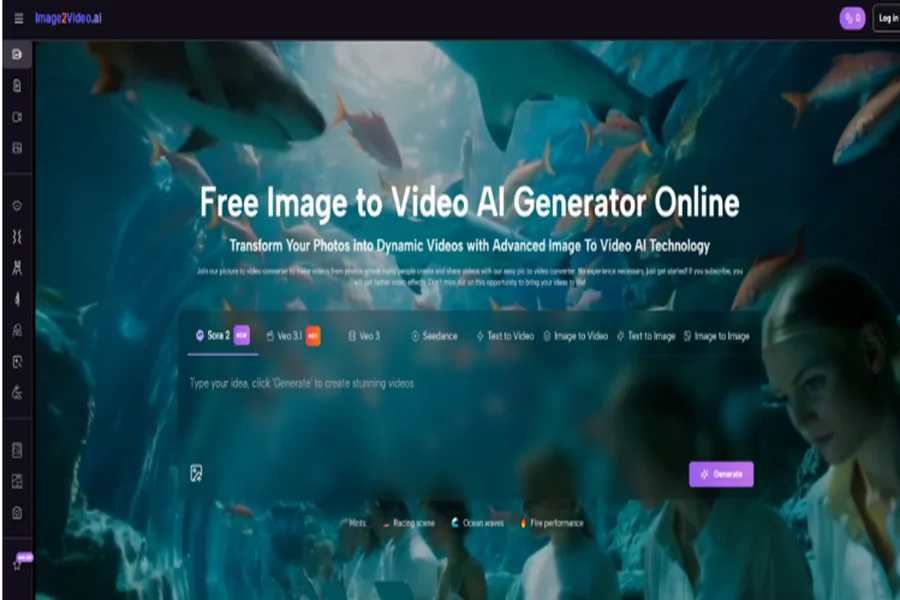
The digital landscape is shifting toward a video-first reality where static images often get lost in the noise. Image to Video AI provides a powerful solution for those who possess high-quality photography but lack the resources for traditional video production. The problem is common: a brand has beautiful product shots, but social media algorithms favor movement. When these images remain still, they face declining reach and engagement. By transforming these assets into short, dynamic clips, creators can revitalize their portfolios and meet the demands of modern viewers who expect visual storytelling to be fluid and alive.
In my tests, the process of turning a still frame into a moving scene feels remarkably intuitive. The technology behind this transition involves deep learning models that have been trained on millions of video clips to understand how light, shadows, and objects move in the real world. When you apply these models to a personal photo, the result is a five-second window into a world that was previously frozen. It looks more stable and professional than simple “Ken Burns” effects, as the AI actually generates new pixels to simulate realistic motion and perspective changes.
Exploring The Versatility Of Modern AI Motion Synthesis Models
The availability of multiple models like Veo 3.1 and Sora 2 on a single platform is a significant advantage for users. Each model has its own “personality” and strengths. Some are better at maintaining the integrity of the original colors, while others are more aggressive in their motion generation. In my experience, experimenting with different prompts can yield vastly different results. For instance, a prompt focusing on “cinematic lighting” can change the mood of the video significantly, even if the base image remains the same. This flexibility is essential for marketers who need to maintain a specific brand aesthetic.
Specialized tools like AI Muscle, AI Hug, and AI Kiss demonstrate the platform’s ability to handle human-centric animation. These are some of the most difficult movements for AI to master because humans are highly sensitive to “uncanny valley” effects in social interactions. While the results are surprisingly good, they do occasionally require a second attempt to ensure the limbs and features remain consistent. This type of Photo to Video capability was previously only available to high-end VFX studios, but it is now accessible to anyone with an internet connection.
A Professional Roadmap For Successful Video Generation Results
To achieve the highest quality output, users should follow the official four-step process. This structure ensures that the AI has all the necessary information to produce a coherent and visually appealing video.
1. Digital Asset Preparation
Upload a high-quality image. The platform specifically supports JPEG and PNG formats. It is helpful to ensure the image is well-composed, as the AI uses the existing layout to determine how the motion should flow.
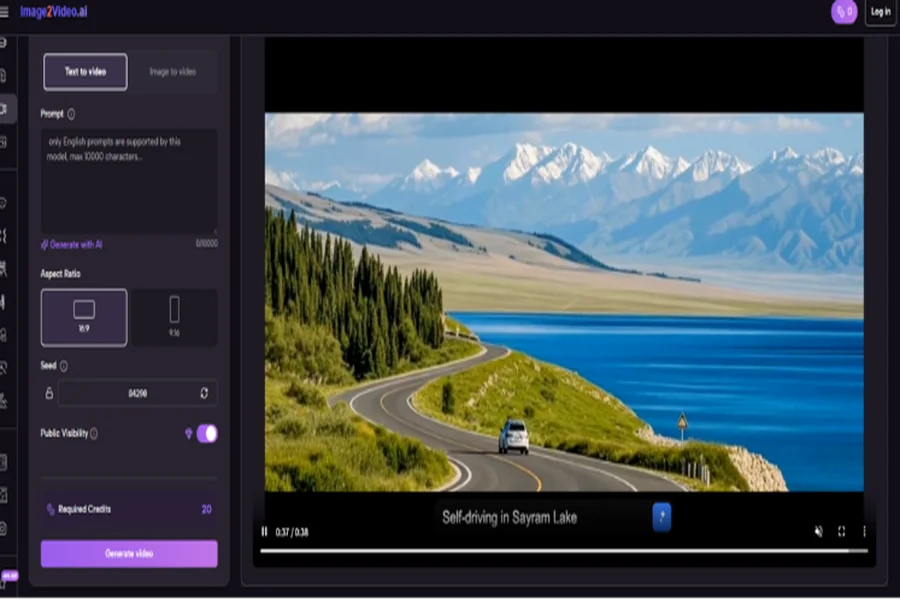
2. Creative Prompt Specification
Describe the movement you wish to see. Using natural language, you can tell the AI to make the subject walk, dance, or simply have the background move. Clear and concise descriptions lead to more predictable and accurate animations.
3. System Synthesis Period
Once the prompt is submitted, the AI begins the processing phase. This typically takes about five minutes. The system is essentially “painting” the frames between the start and end of the motion to create a smooth MP4 file.
4. Review And Final Export
When the status shows as completed, the video is ready. Users can check the motion for any artifacts and then download the 5-second clip for use on social media, websites, or digital advertisements.
Feature Comparison Of Integrated AI Video Generation Tools
| Tool Attribute | Manual Animation | Image2Video AI Integration |
| Skill Requirement | High Technical Proficiency | No Experience Required |
| Generation Speed | Hours or Days | Under 5 Minutes |
| File Support | Most Image Formats | JPEG / PNG to MP4 |
| Motion Quality | Depends on Editor | AI Model Driven (Veo/Sora) |
| Accessibility | Expensive Software | Web-Based / Mobile Ready |
Navigating The Current Landscape Of Generative Video Technology
As with any emerging technology, there are limitations to be aware of. The current five-second limit is excellent for short-form content but may not suit those looking to create long-form documentaries without significant post-production work. Additionally, the success of the animation is highly dependent on the quality of the prompt; vague instructions can sometimes lead to unexpected or surreal results. It is also important to note that the system does not currently support adding custom audio tracks, so users will need to add music or voiceovers using external editors if desired.
The future of this field is focused on increasing the duration of clips and improving the “temporal consistency”—meaning the video stays sharp and consistent from the first second to the last. Trends in the industry suggest that we will soon see even more control over specific object movements within a frame. For now, the ability to quickly and easily convert a static image into a cinematic experience is a game-changer for digital storytelling, allowing a wider range of people to share their vision in a dynamic, engaging format.